1. Introducción
Hola a todos y bienvenido a un nuevo post de nuestro querido blog!. En esta ocasión vamos a utilizar el Sharding sobre una de nuestras colecciones con el fin de llevar a cabo el escalamiento de nuestro sistema. La idea principal consiste en repartir un dataset a lo largo de distintos clusters, que denominamos shards, de tal forma que exista una distribución de los datos equitativa a lo largo de los distintos nodos. Por tanto el sharding nos permite mejorar el rendimiento de nuestro sistema ya que al distribuir la carga entre distintas máquinas no existe sobrecarga de un nodo.
Elementos de la arquitectura
- Mongos: Son las instancias que hacen de interfaz entre los shards donde se encuentran los datos y las aplicaciones de tal forma que éstas deben conectarse a los endpoints de los mongos. Son muy ligeras y suelen desplegarse dentro de las máquinas donde se encuentra el servidor de aplicaciones. Puede desplegarse en forma de réplica.
- Config Server: Son instancias mongod que contienen metadatos asociados al dataset. Básicamente indican la localización de los documentos en base a shards o chunks. Puede desplegarse en forma de réplica.
- Shards: Son los clusters en donde se encuentra los documentos de nuestras colecciones. Cada cluster contiene un subconjunto del dataset. La información dentro de un cluster se agrupa en torno a agrupaciones lógicas denominados chunks. Por defecto dichos chunks tienen un tamaño de 64MB. El tamaño de éstos determina la realización de subdivisiones, creando nuevos chunks, y la migración de éstas entre shards.
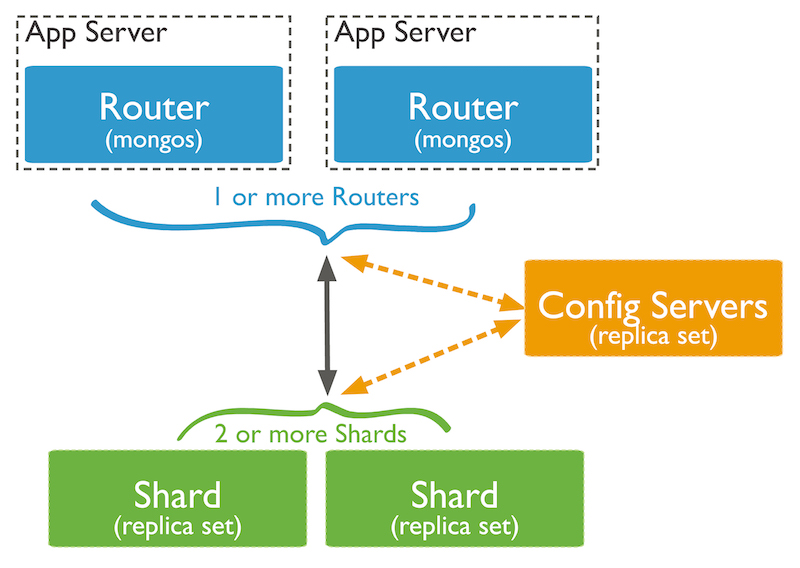
Las acciones que deben tener lugar para que la información se distribuya entre los clusters son:
- Split Chunks: La subdivisión de chunks se produce cuando se sobrepasa el tamaño del mismo ya que existe un exceso de documentos.
- Migration Chunks: La migración es el procedimiento de distribuir un chunk de un shard a otro. Este proceso lo lleva a cabo un proceso denominado balancer ubicado en el nodo primario del Config Server. Cuando este proceso detecta que la diferencia entre el número de chunks del shard que más tiene con el que menos tiene sobrepasa un umbral, se inicia la migración. Cuando el número total de chunks es menor de 20 el umbral es de 2. Para más info ampliar aquí.
¿Sobre qué nivel trabaja el Sharding?
Trabaja a nivel de colección de tal forma que podemos decidir que colecciones queremos distribuir y cuales no. Las colecciones que no se encuentran distribuidas siempre se encontrarán en el shard primario.
Elección de la Shared Key
Uno de los puntos más importantes a la hora de clusterizar una colección en MongoDB es elegir la shared key que será el instrumento que se utilizará para distribuir la información. Se recomienda que una Shared Key cumpla una serie de criterios:
- Alta cardinalidad
- Baja frecuencia
- Evitar crecimiento monótono
Para más información visitar el manual de mongo.
Tecnologías empleadas:
- MongoDB 3.6
2. Requisitos previos
2.1 Instalación
Es necesario tener los binarios de MongoDB en nuestra máquina. Si no los tiene bájatelos de los web oficial y descomprímelos dentro de un directorio de trabajo.
2.2 Preparación entorno
Cada instancia de mongo necesita un directorio de trabajo (dbpath) sobre el cual trabajar. Creamos los siguientes asignándoles permisos de lectura / escritura.
rm -rf /data/config rm -rf /data/shard* mkdir -p /data/shard0 /data/shard0/rs0 /data/shard0/rs1 /data/shard0/rs2 mkdir -p /data/shard1 /data/shard1/rs0 /data/shard1/rs1 /data/shard1/rs2 mkdir -p /data/shard2 /data/shard2/rs0 /data/shard2/rs1 /data/shard2/rs2 mkdir -p /data/config /data/config/rs0 /data/config/rs1 /data/config/rs2 chmod -R 777 /data/shard0 chmod -R 777 /data/shard1 chmod -R 777 /data/shard2 chmod -R 777 /data/config
3. Sharding sobre una colección de usuarios
Vamos a distribuir los documentos de la colección users de la base de datos mybd a los largo de diferentes shards. Para ellos crearemos:
- Dos shards con un replica set de tres nodos por shard.
- Un replica set de tres nodos para el config server.
- Una instancia mongos
En primer lugar eliminamos las instancias mongod y mongos que pudiesen existir en nuestro sistema.
Configuramos el primer shard desplegando un replica set de tres nodos.
mongod --replSet s0 --dbpath /data/shard0/rs0 --port 37017 --shardsvr
mongod --replSet s0 --dbpath /data/shard0/rs1 --port 37018 --shardsvr
mongod --replSet s0 --dbpath /data/shard0/rs2 --port 37019 --shardsvr
mongo --port 37017
config = { _id: "s0", members:[
{ _id : 0, host : "localhost:37017" },
{ _id : 1, host : "localhost:37018" },
{ _id : 2, host : "localhost:37019" }]};
rs.initiate(config)
Configuramos el segundo shard desplegando un replica set de tres nodos.
mongod --replSet s1 --dbpath /data/shard1/rs0 --port 47017 --shardsvr
mongod --replSet s1 --dbpath /data/shard1/rs1 --port 47018 --shardsvr
mongod --replSet s1 --dbpath /data/shard1/rs2 --port 47019 --shardsvr
mongo --port 47017
config = { _id: "s1", members:[
{ _id : 0, host : "localhost:47017" },
{ _id : 1, host : "localhost:47018" },
{ _id : 2, host : "localhost:47019" }]};
rs.initiate(config)
Configuramos el config server como un replica set de tres nodos.
mongod --replSet csReplSet --dbpath /data/config/rs0 --port 57040 --configsvr
mongod --replSet csReplSet --dbpath /data/config/rs1 --port 57041 --configsvr
mongod --replSet csReplSet --dbpath /data/config/rs2 --port 57042 --configsvr
mongo --port 57040
config = { _id: "csReplSet", members:[
{ _id : 0, host : "localhost:57040" },
{ _id : 1, host : "localhost:57041" },
{ _id : 2, host : "localhost:57042" }]};
rs.initiate(config)
Creamos una instancia mongos indicando los nodos que forman parte del config server.
Registramos los dos shard creados en nuestra instancia de mongos.
mongo
mongos> use admin
mongos> sh.addShard("s0/localhost:37017");
mongos> sh.addShard("s1/localhost:47017");
Creamos la base de datos mybd y la colección users sobre la que aplicaremos el Sharding. Deberemos crear un índice sobre ella ya que es condición necesaria que exista uno cuyo prefijo sea la shared key para poder llevar a cabo la distribución de los datos a lo largo de los shards. Además insertamos 10000 registros para que se pueda llevar a cabo la distribución.
mongos> use mybd;
mongos> db.users.createIndex({user_id: 1});
mongos> for(var i = 0; i < 10000; i++)db.users.insert({user_id: i, name: "name_" + i});
En este momento los datos se encuentran dentro del shard primario ya que no hemos habilitado todavía el sharding sobre esta colección.
Para favorecer la distribución de los datos establecemos un tamaño de chunk de 1mb ya que por defecto es de 64mb. Dicho tamaño determina la cantidad de divisiones y migraciones de chunks que se van a realizar.
mongos> use config
mongos> switched to db config
mongos> db.settings.save( { _id:"chunksize", value: 1 } )
Definitivamente llevamos a cabo el sharding sobre la colección users de la base de datos mybd.
Por último podemos ver el estado de los shards así como los rangos a través del comando sh.status() relacionando cada rango con un shard.
mongos> sh.status()
{ "_id" : "mybd", "primary" : "s1", "partitioned" : true }
mybd.users
shard key: { "user_id" : 1 }
unique: false
balancing: true
chunks:
s1 5
{ "user_id" : { "$minKey" : 1 } } -->> { "user_id" : 0 } on : s1 Timestamp(1, 1)
{ "user_id" : 0 } -->> { "user_id" : 3013 } on : s1 Timestamp(1, 4)
{ "user_id" : 3013 } -->> { "user_id" : 7252 } on : s1 Timestamp(1, 5)
{ "user_id" : 7252 } -->> { "user_id" : 9039 } on : s0 Timestamp(1, 6)
{ "user_id" : 9039 } -->> { "user_id" : { "$maxKey" : 1 } } on : s0 Timestamp(1, 3)
Si llevamos a cabo un recuerto que todos los documentos el resultado deberá ser 10000
4. Acceso al servidor de configuración
Tal y como se indica en la documentación no es recomentable acceder directamente a los nodos del servidor de configuración para llevar a cabo cualquier tipo de operativa sobre sus bases de datos. Se recomienda acceder a través de la instancia mongos y cambiando a la base de datos config tal y como se muestra:
mongos> use config; switched to db config mongos> show collections; actionlog changelog chunks collections databases lockpings locks migrations mongos settings shards tags transactions version
De esta forma podemos acceder a todas las colecciones que permiten llevar a cabo la distribución y mantenimiento de los documentos a través de los shards.