1. Introducción
Hola a todos y bienvenido a un nuevo post de nuestro querido blog!. En esta ocasión vamos a montar un cluster de Spark sobre máquinas EC2 en AWS empleando packer, ansible y terraform para crear la infraestructura. Además instanciaremos una máquina ec2 donde instalaremos Jupyter para verificar el funcionamiento nuestro cluster. Este es un post que tiene muchas tecnologías y muchos pasos así que habrá que ir poco a poco.
Os podéis descargar el código de ejemplo de mi GitHub aquí.
Tecnologías empleadas:
- Java 8
- Python 3.6
- Spark 2.4.3
- Terraform 0.12.4
- Packer 1.4.2
- Ansible 2.8.2
Entorno de desarrollo:
- Ubuntu 16.04
2. Prerequisitos
Es necesario que tengáis acceso a una cuenta AWS a través del cli y de la propia consola. Podéis ver como configurarlo ir al post Terraform – Hello World!.
3. Instalación
Antes de empezar es necesario instalar en nuestra máquina Terraform y Packer.
Terraform
$ cd /opt $ wget https://releases.hashicorp.com/terraform/0.12.4/terraform_0.12.4_linux_amd64.zip $ unzip terraform_0.12.4_linux_amd64.zip $ ln -s /opt/terraform /usr/local/bin/terraform
Packer
$ cd /opt $ wget https://releases.hashicorp.com/packer/1.4.2/packer_1.4.2_linux_amd64.zip $ unzip packer_1.4.2_linux_amd64.zip $ ln -s /opt/packer /usr/local/bin/packer
Verificamos la instalación
3. Packer. Creación AMI
Packer es un software desarrollado por Hashicorp que nos permite construir AMIS a través de código.
La idea será construir la imagen base de los nodos de nuestro cluster de Spark delegando el aprovisionamiento en ansible. Esto se consigue a través del provisioner ansible-local.
Código
{
"variables": {
"version": "0.1.0",
"region": "{{ env `AWS_REGION`}}",
"environment": "{{ env `ENVIRONMENT`}}"
},
"builders": [{
"name": "spark",
"temporary_security_group_source_cidrs": "{{ user `public_ip_cidr` }}",
"type": "amazon-ebs",
"region": "{{user `region`}}",
"ami_name": "spark-{{timestamp}}",
"source_ami_filter": {
"filters": {
"virtualization-type": "hvm",
"name": "ubuntu/images/hvm-ssd/ubuntu-bionic-18.04-amd64-server*",
"root-device-type": "ebs"
},
"owners": ["099720109477"],
"most_recent": true
},
"instance_type": "t3.micro",
"ssh_username": "ubuntu",
"ssh_pty": false,
"tags": {
"ami_purpose": "spark",
"ami_version" : "{{user `version`}}"
}
}],
"provisioners": [{
"type": "shell",
"inline": [
"echo 'debconf debconf/frontend select Noninteractive' | sudo debconf-set-selections",
"sudo rm /var/cache/debconf/*.dat",
"sudo apt-get install -y -q",
"sleep 20",
"sudo apt-get update",
"sudo apt-get install python-pip -y",
"sudo -H pip install ansible"
]
},
{
"type": "ansible-local",
"playbook_file": "ansible/spark.yml",
"playbook_dir": "ansible",
"extra_arguments": [ "--extra-vars \"Environment={{user `environment`}}\"" ]
}]
}
Ver que hemos especificado los tags ami_purpose y ami_version que nos servirán más adelante para seleccionar la ami desde terraform.
Fichero de configuración de ansible donde instalaremos python3, pip3, java8, scala, spark y setearemos la variable de entorno PYSPARK_PYTHON
---
- hosts: all
become: yes
vars_files:
- "vars/spark_vars.yml"
tasks:
- name: Install a list of packages
apt:
name: "{{ packages }}"
vars:
packages:
- python3-pip
- openjdk-8-jdk
- scala
- name: Download spark zip
get_url:
url: "{{ bin_spark_url }}"
dest: /opt
- name: Extract bin spark
unarchive:
src: /opt/{{ zip_name }}
dest: /opt
- name: Set environment variable PYSPARK_PYTHON
lineinfile:
path: /etc/environment
line: PYSPARK_PYTHON=python3
---
zip_name: spark-2.4.3-bin-hadoop2.7.tgz
bin_spark_url: http://apache.rediris.es/spark/spark-2.4.3/{{ zip_name }}
Ejecución
Ejecutamos la construcción de la AMI
$ export AWS_REGION="eu-west-1" $ packer build -var public_ip_cidr=$(curl -s ifconfig.co)/32 spark.json
Al terminar la ejecución veremos nuestro imagen en AWS

4. Terraform
Vamos a crear un cluster de Spark con un maestro y un esclavo que se encontrarán en una subred privada. Además crearemos otra máquina dentro de una subred pública donde instalaremos Jupyter con el fin de probar nuestra instalación. Antes de empezar será necesario crear un par de claves dentro del directorio terraform.
Código
Fichero tf
Fichero de variables
variable "AWS_REGION" {
default = "eu-west-1"
}
variable "SPARK_TAG_AMI_VERSION"{
default = "0.1.0"
}
variable "PATH_TO_PUBLIC_KEY" {
default = "mykey.pub"
}
variable "SPARK_BIN" {
default = "spark-2.4.3-bin-hadoop2.7"
}
variable "PUBLIC_IP_CIDR"{
default = "0.0.0.0/0"
}
El proveedor es aws
Creamos un par de clave y le asociamos la clave pública. La privada nos servirá para conectarnos a la instancia
resource "aws_key_pair" "mykeypair"{
key_name = "mykey"
public_key = "${file("${var.PATH_TO_PUBLIC_KEY}")}"
}
Creamos la vpc my-vpc y 3 subredes públicas y privadas a través del módulo terraform-aws-modules/vpc/aws
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "my-vpc"
cidr = "10.0.0.0/16"
azs = ["eu-west-1a", "eu-west-1b", "eu-west-1c"]
private_subnets = ["10.0.1.0/24", "10.0.2.0/24", "10.0.3.0/24"]
public_subnets = ["10.0.101.0/24", "10.0.102.0/24", "10.0.103.0/24"]
enable_nat_gateway = false
enable_vpn_gateway = false
enable_dns_hostnames = true
}
Creamos un firewall para las nodos del cluster y otro para la máquina donde instalaremos jupyter. Es importante abrir todos los puertos ya que Spark trabaja con rpc y los nodos se comunican a través de cualquier puerto.
resource "aws_security_group" "spark-sg" {
vpc_id = "${module.vpc.vpc_id}"
name = "spark-sg"
description = "Spark master security group"
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_security_group" "jupyter-sg" {
vpc_id = "${module.vpc.vpc_id}"
name = "jupyter-sg"
description = "jupyter-sg"
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 0
to_port = 0
protocol = "-1"
security_groups = ["${aws_security_group.spark-sg.id}"]
}
ingress {
from_port = 8888
to_port = 8888
protocol = "tcp"
cidr_blocks = ["${var.PUBLIC_IP_CIDR}"]
}
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["${var.PUBLIC_IP_CIDR}"]
}
}
Especificamos la ami que hemos creado en el punto anterior filtrando por los tag ami_purpose seleccionando la versión más reciente. Creamos tres máquinas
- spark-master
- spark-slave
- jupyter
data "aws_ami" "spark_ami" {
most_recent = true
filter {
name = "tag:ami_purpose"
values = ["spark"]
}
filter {
name = "tag:ami_version"
values = ["${var.SPARK_TAG_AMI_VERSION}"]
}
owners = ["self"]
}
data "template_file" "spark_master_init" {
template = "${file("script/spark_master_init.tpl")}"
vars = {
spark_bin = "${var.SPARK_BIN}"
}
}
data "template_file" "spark_slave_init" {
template = "${file("script/spark_slave_init.tpl")}"
vars = {
spark_master_private_dns = "${aws_instance.spark_master.private_dns}"
spark_bin = "${var.SPARK_BIN}"
}
}
data "template_file" "jupyter_init" {
template = "${file("script/jupyter_init.tpl")}"
}
resource "aws_instance" "spark_master" {
ami = "${data.aws_ami.spark_ami.id}"
instance_type = "t3.medium"
key_name = "${aws_key_pair.mykeypair.key_name}"
vpc_security_group_ids = ["${aws_security_group.spark-sg.id}"]
subnet_id = "${module.vpc.private_subnets[0]}"
user_data = "${data.template_file.spark_master_init.rendered}"
tags = {
"Name" = "spark-master"
}
}
resource "aws_instance" "spark_slave" {
ami = "${data.aws_ami.spark_ami.id}"
instance_type = "t3.medium"
key_name = "${aws_key_pair.mykeypair.key_name}"
vpc_security_group_ids = ["${aws_security_group.spark-sg.id}"]
subnet_id = "${module.vpc.private_subnets[0]}"
user_data = "${data.template_file.spark_slave_init.rendered}"
tags = {
"Name" = "spark-slave"
}
depends_on = [aws_instance.spark_master]
}
resource "aws_instance" "jupyter" {
ami = "${data.aws_ami.spark_ami.id}"
instance_type = "t3.medium"
key_name = "${aws_key_pair.mykeypair.key_name}"
vpc_security_group_ids = ["${aws_security_group.jupyter-sg.id}"]
subnet_id = "${module.vpc.public_subnets[0]}"
user_data = "${data.template_file.jupyter_init.rendered}"
tags = {
"Name" = "jupyter"
}
}
El aprovisionamiento de la máquina jupyter la hacemos a través del user-data por simplicidad.
Fichero de salida de variables
output "spark-master" {
value = "${aws_instance.spark_master.public_dns}"
}
output "private-ip-spark-master" {
value = "${aws_instance.spark_master.private_ip}"
}
output "private-ip-spark-slave" {
value = "${aws_instance.spark_slave.private_ip}"
}
output "jupyter" {
value = "${aws_instance.jupyter.public_dns}"
}
Fichero de arranque del maestro. Arrancamos spark como maestro
#!/bin/bash
/opt/${spark_bin}/sbin/start-master.sh -h $(curl http://169.254.169.254/latest/meta-data/hostname)
Fichero de arranque del esclavo. Arrancamos spark como esclavo indicando donde se encuentra el maestro
Fichero de arranque del jupyter. Por simplicidad aprovechamos este punto para aprovisionar la máquina
#!/bin/bash sudo apt-get update sudo apt-get install python3-pip sudo apt-get install openjdk-8-jdk sudo -H pip3 install jupyter sudo -H pip3 install pyspark mkdir /home/ubuntu/.jupyter touch /home/ubuntu/.jupyter/jupyter_notebook_config.py chown ubuntu:ubuntu /home/ubuntu/.jupyter chown ubuntu:ubuntu /home/ubuntu/.jupyter/jupyter_notebook_config.py echo "c = get_config()" >> /home/ubuntu/.jupyter/jupyter_notebook_config.py echo "c.NotebookApp.ip = '0.0.0.0'" >> /home/ubuntu/.jupyter/jupyter_notebook_config.py echo "c.NotebookApp.open_browser = False" >> /home/ubuntu/.jupyter/jupyter_notebook_config.py echo "c.NotebookApp.port = 8888" >> /home/ubuntu/.jupyter/jupyter_notebook_config.py export PYSPARK_DRIVER_PYTHON="jupyter" export PYSPARK_DRIVER_PYTHON_OPTS="notebook" export PYSPARK_PYTHON=python3
Ejecución
Ya solo falta ejecutar terraform para crear la infra!
Obtenemos las salidas especificadas
Outputs: jupyter = ec2-63-35-227-194.eu-west-1.compute.amazonaws.com private-ip-spark-master = 10.0.1.228 private-ip-spark-slave = 10.0.1.83 spark-master = ip-10-0-1-228.eu-west-1.compute.internal
Una vez terminada verificamos que se han creado las tres máquinas.

5. Verificación de la instalación
Nos conectamos a la máquina donde está instalado el Jupyter a través de la clave privada que creamos en el paso anterior. El host lo obtenemos de las salidas del terraform.
Lanzamos jupyter
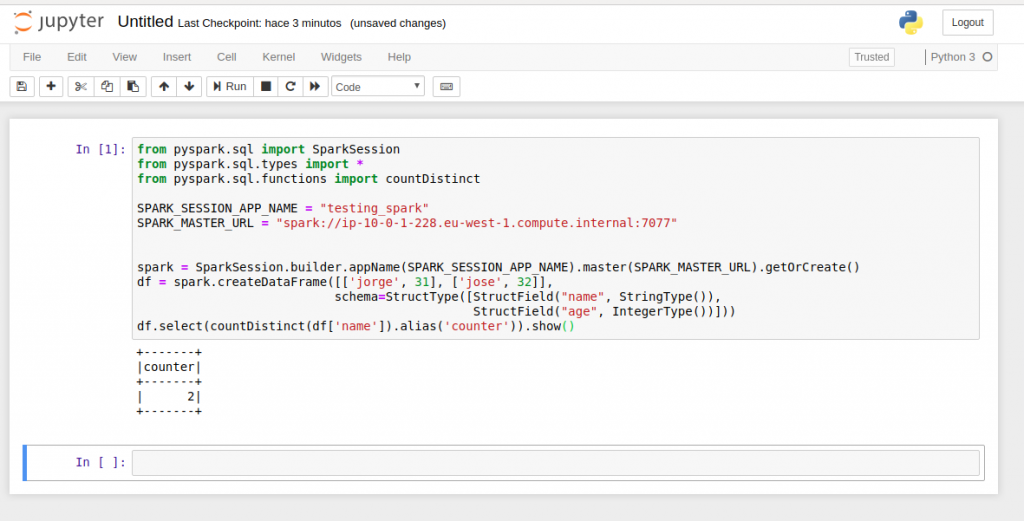
Abrimos la siguiente dirección en un navegador http://ec2-63-35-227-194.eu-west-1.compute.amazonaws.com:8888 e introducimos el token que obtenemos por consola. Creamos un Notebook sobre python3 y ejecutamos el siguiente código. La variable SPARK_MASTER_URL habrá que actualizarla por el host privado del nodo maestro
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import countDistinct
SPARK_SESSION_APP_NAME = "testing_spark"
SPARK_MASTER_URL = "spark://ip-10-0-1-112.eu-west-1.compute.internal:7077"
spark = SparkSession.builder.appName(SPARK_SESSION_APP_NAME).master(SPARK_MASTER_URL).getOrCreate()
df = spark.createDataFrame([['jorge', 31], ['jose', 32]],
schema=StructType([StructField("name", StringType()),
StructField("age", IntegerType())]))
df.select(countDistinct(df['name']).alias('counter')).show()
Lo que hace el código es crear un dataframe de usuarios con las columnas nombre y edad. El objetivo es calcular el número de usuarios distintos dentro del dataframe. Ejecutamos el código y finalmente obtenemos