1. Introducción
Hola a todos y bienvenidos a un nuevo post de nuestro querido blog!. En esta ocasión vamos a proceder a instalar Spark en modo local en nuestro Mac, aunque los pasos se podrán reproducir en otros sistemas operativos fácilmente como Ubuntu o cualquier distribución Linux.
Tecnologías empleadas:
- Python 3
- Java 8
- Spark 2.4.4
- PySpark 2.4.4
2. Requisitos previos
Para instalar Spark es necesario disponer de la JDK 8. En mi caso contaba con las versiones 8 y 10 de Java así que si quieres ver como se gestionan distintas versiones de la JDK puedes ir al post Gestionar varias JDK en Mac
Para verificar que tenemos la versión de Java 8 en nuestro sistema hacemos
3. Instalación
Descargamos Spark en /opt
$ cd /opt $ curl -O http://apache.rediris.es/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz $ tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz
Instalamos las variables de entorno necesarios para que la sesión de Spark pueda conectarse con el cluster
Si tienes Java 8 instalado no es necesario el siguiente paso. Solo llevar a cabo en el caso de disponer de distintas JDK en tu sistema
] $ touch /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh $ echo 'JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home' > /opt/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
4. Probando nuestro cluster en modo local
Creamos un virtualenv donde instalar pyspark
] $ virtualenv -p python3 ~/myvirtualenv $ source ~/myvirtualenv/bin/activate $(virtualenv) pip install pyspark
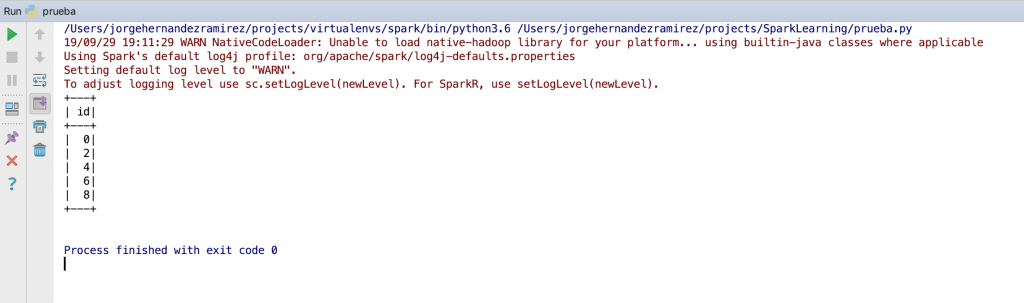
Abrimos el pycharm y ejecutamos el siguientes script haciendo uso del virtualenv anterior
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("learning").master("local").getOrCreate()
spark.range(0, 10, 2).show()
Obteniendo